Background
One business unit in our teams has a technical stack of DUBBO/SpringBoot/Nginx. They have a traffic over 2000 requests/sec and 300 requests/sec(QPS) per instance serving through HTTP. Several DUBBO invocations might be made during one request. The average response time(RT) for top 2 entries is 6.23ms / 250ms. And the RT may increase to 50ms / 600ms in peak minutes.
So they have already figured to optimize it for days.
Invocation chain optimization
First we checked and analysis the invocation chain. In most cases unstable RT may first due to the inefficient link chain: short connection, overflowed connection table, inappropriate send/recv buffer, synchronous IO waiting, problematic internal network and so on.
NGINX
The first spot of the incoming traffic is the NGINX nodes. They maintain the connections used by HTTP requests from clients(APP or partner) directly.
The keepalive is set to 3 seconds and I increase it to 10 seconds to make a longer life of them avoiding unnecessary reconnecting. And it can be observed that the count connections between NGINX and java applications is still an unignore level.
To make them persistent I add keepalive 60 configuration into the upstream block in nginx configuration and
proxy_http_version 1.1;
proxy_set_header Connection "";
to proxying configuration to enable HTTP1.1 and connection pool (holding) feature. Please pay attention that the keepalive here is not the same meaning in other scenario which means the maximum connections held on during serving. So we set it into 60 and actually they will not be shared between nginx workers. And the upstream nodes must support keepalive feature which is available from HTTP1.1 and we must add the Connection header to support it.
After enabling HTTP1.1 between NGINX and java applications the connections became more “persistent” and the RT reduced to 2.6ms / 260ms in average. And we also make it smoother in peak minutes.
During this process I found that though it has gain a better performance in RT it still costs so much CPU time and especially high cpu switching count.
Asynchronous
To reduce the switching count I dig into the instance process more and found there was a thread pool with over 500 threads in it. It's used to accelerate the request processing on parallel invocation of DUBBO/Http.
Actually thread pool should not be introduced here because all runnable threads are still waiting for the responses and asynchronous model should be used here. HttpClient can be enhanced by introducing async-http-client and DUBBO invocation can be called in asynchronous way. All we need to do is to dispatch the asynchronous calls out and to wait them to complete/fail.
RT had been reduced to 2.3ms / 170ms after this.
And again my eyes are on the frequency of YGC of JVM.
YGC frequency
They had optimized the JVM arguments on memory quota with mx=1400m ms=1400m mn=1g after a few iterations to avoid unnecessary old generation space and more eden space.
Instance under average QPS(about 500 in average, with 800MB in memory) the YGC cycle keep a period about 30~38 seconds. Because the codes are quite simple and optimized I feel a little curious on what kinds of short-lifetime objects are in the Eden.
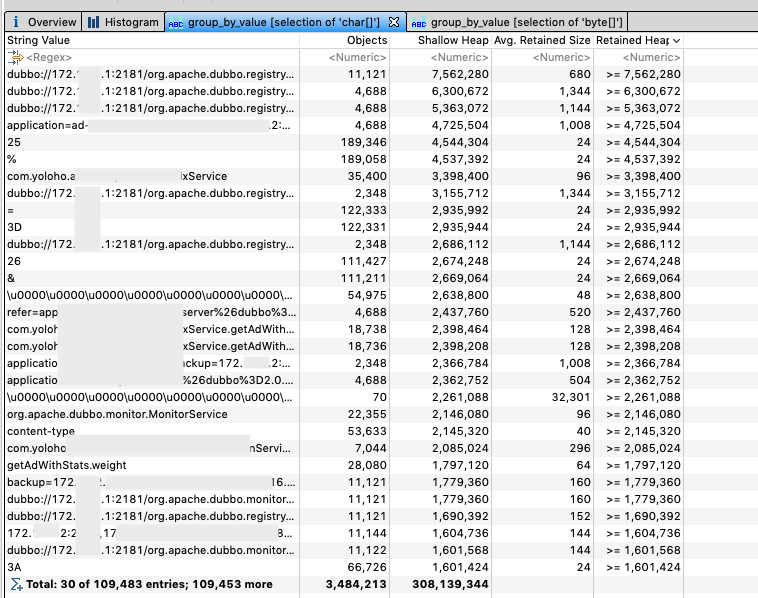
After some attempts of sampling the result is shown below including unreachable objects:
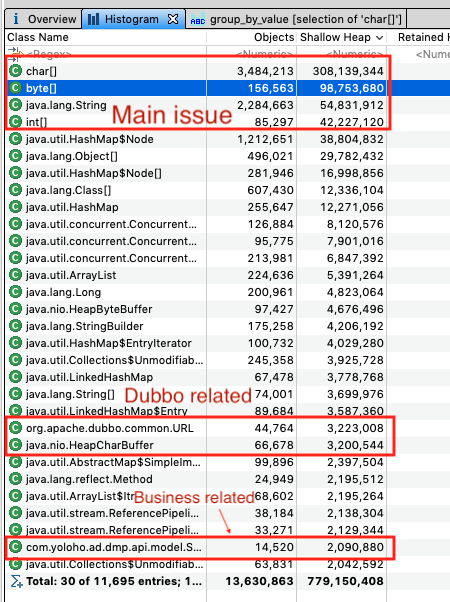
Here we can see the top N types of objects in retaining of memory and found that the curve of it is very steep and clustered in char[] / byte[] / String.
Temporary Objects in Heap
We can see visually there are obvious topN head in count of the objects in heap as below:
There are mainly two reasons generating so many char[] / string:
- There are many joint of string for configuration name like
versionanddefault.versionwhich is joined bydefault.andversion. We can avoid it by build a LRU cache for it. - There is unnecessary temporary object in monitor filter. We can rewrite it to reuse object.
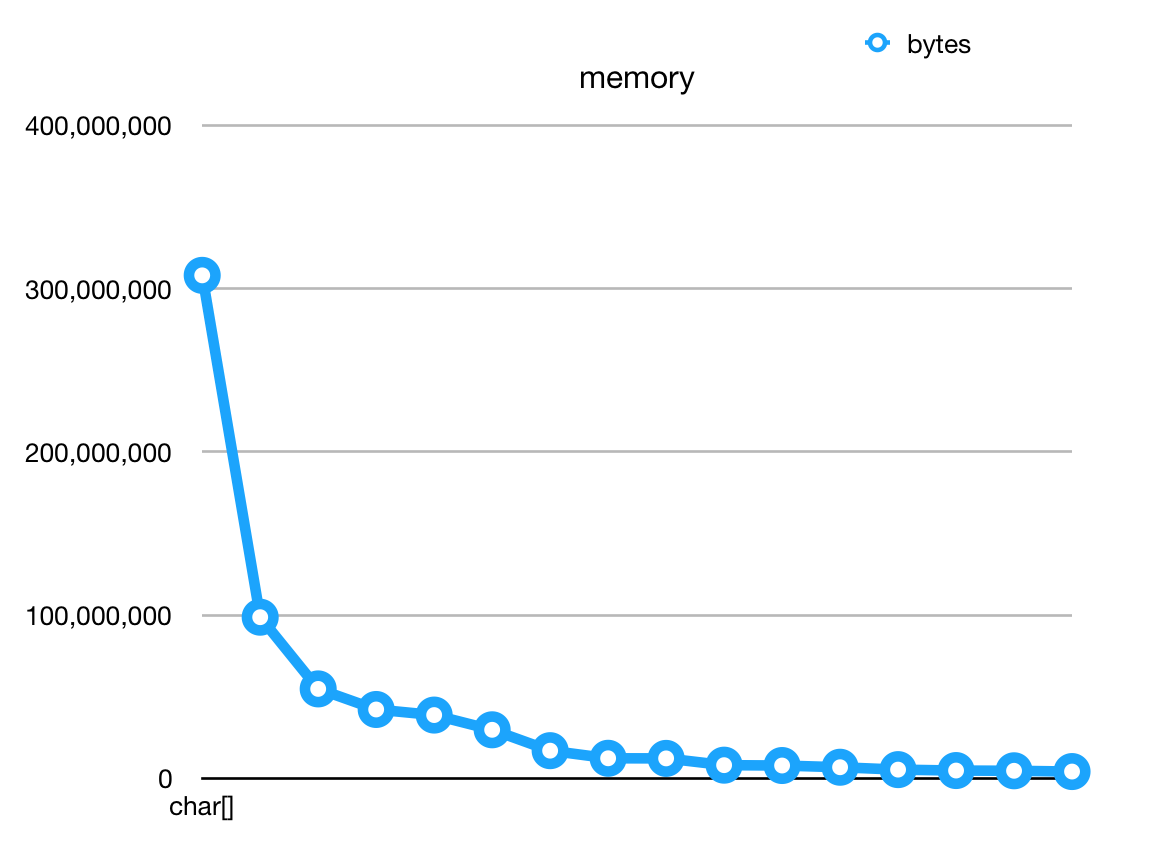
By doing this we got a new chart:
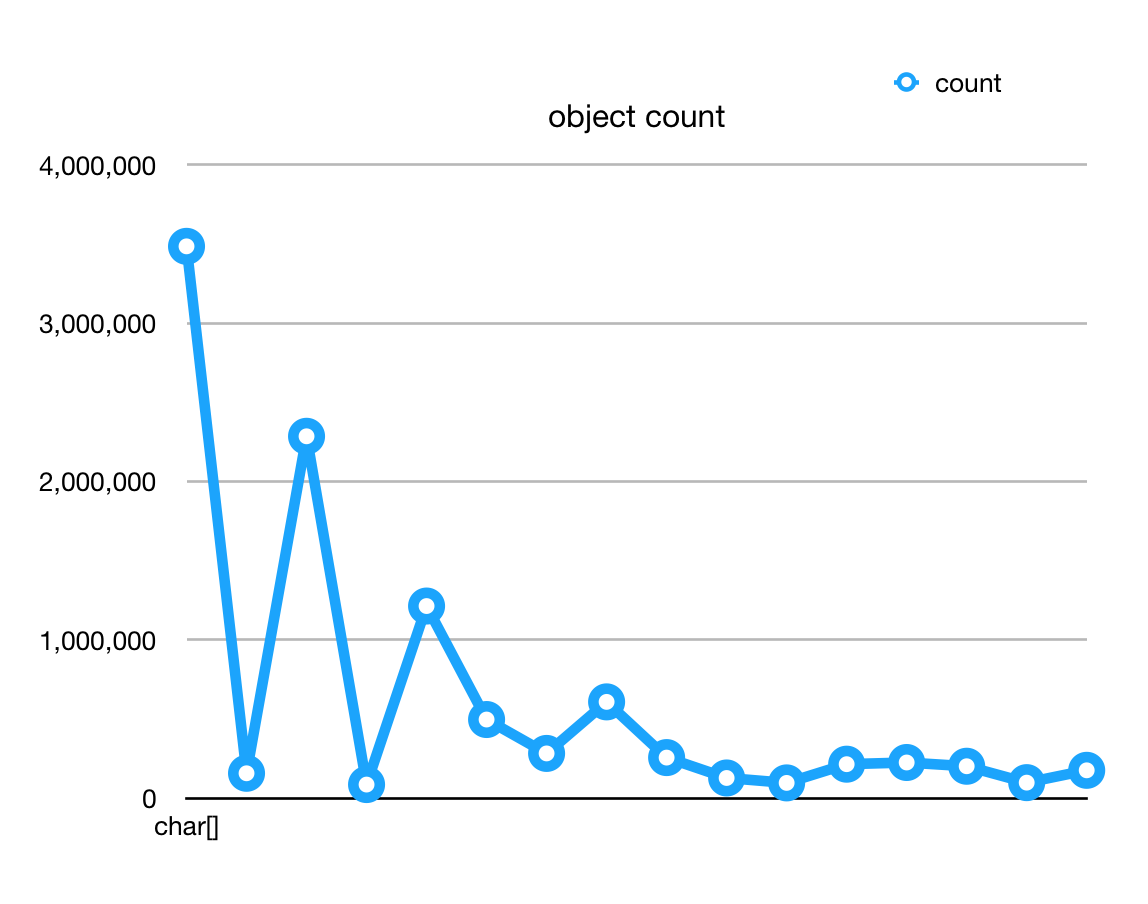
It showed that the top N objects isn't significant any more. And the FGC period is triple than before.
Remained
Though the YGC is improved a lot but there are still some space to go further. We captured another objects unreachable byte[]:
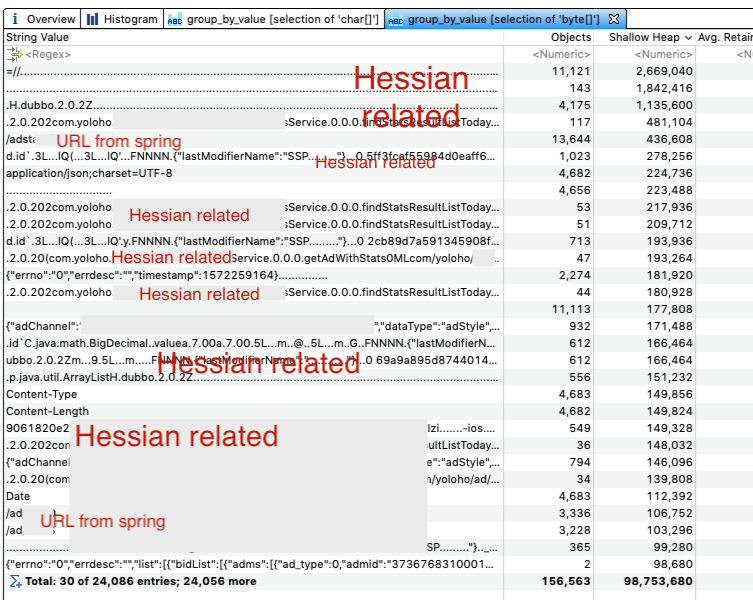
URL
URL is an issued design because it's designed to be immutable now and every modification on it will generates a new instance. So related blocks should be paid more attention and better to use URLBuilder obviously.
Hessian2
Hessian2ObjectInput / Hessian2ObjectOutput are heavy and can cause visible pressure to YGC on a high QPS instance. So making them reusable or any other optimization is a worth thing in future. Surely for those default serialization protocol users.